搜索到
6
篇与
的结果
-
 排序算法 - 1.冒泡排序 冒泡排序是最简单的排序方法,理解起来容易。虽然它的计算步骤比较多,不是最快的,但它是最基本的,初学者一定要掌握。 冒泡排序的原理是:从左到右,相邻元素进行比较。每次比较一轮,就会找到序列中最大的一个或最小的一个。这个数就会从序列的最右边冒出来。 以从小到大排序为例,第一轮比较后,所有数中最大的那个数就会浮到最右边;第二轮比较后,所有数中第二大的那个数就会浮到倒数第二个位置……就这样一轮一轮地比较,最后实现从小到大排序。 # include <stdio.h> int main(void) { int a[] = {900, 2, 3, -58, 34, 76, 32, 43, 56, -70, 35, -234, 532, 543, 2500}; int n; //存放数组a中元素的个数 int i; //比较的轮数 int j; //每轮比较的次数 int buf; //交换数据时用于存放中间数据 n = sizeof(a) / sizeof(a[0]); /*a[0]是int型, 占4字节, 所以总的字节数除以4等于元素的个数*/ for (i=0; i<n-1; ++i) //比较n-1轮 { for (j=0; j<n-1-i; ++j) //每轮比较n-1-i次, { if (a[j] < a[j+1]) { buf = a[j]; a[j] = a[j+1]; a[j+1] = buf; } } } for (i=0; i<n; ++i) { printf("%d\x20", a[i]); } printf("\n"); return 0; } 算法分析 冒泡排序一共要进行(n-1)次循环,每一次循环都要进行当前n-1次比较所以一共的比较次数是:(n-1) + (n-2) + (n-3) + … + 1 = n*(n-1)/2;所以冒泡排序的时间复杂度是 O(n^2)
排序算法 - 1.冒泡排序 冒泡排序是最简单的排序方法,理解起来容易。虽然它的计算步骤比较多,不是最快的,但它是最基本的,初学者一定要掌握。 冒泡排序的原理是:从左到右,相邻元素进行比较。每次比较一轮,就会找到序列中最大的一个或最小的一个。这个数就会从序列的最右边冒出来。 以从小到大排序为例,第一轮比较后,所有数中最大的那个数就会浮到最右边;第二轮比较后,所有数中第二大的那个数就会浮到倒数第二个位置……就这样一轮一轮地比较,最后实现从小到大排序。 # include <stdio.h> int main(void) { int a[] = {900, 2, 3, -58, 34, 76, 32, 43, 56, -70, 35, -234, 532, 543, 2500}; int n; //存放数组a中元素的个数 int i; //比较的轮数 int j; //每轮比较的次数 int buf; //交换数据时用于存放中间数据 n = sizeof(a) / sizeof(a[0]); /*a[0]是int型, 占4字节, 所以总的字节数除以4等于元素的个数*/ for (i=0; i<n-1; ++i) //比较n-1轮 { for (j=0; j<n-1-i; ++j) //每轮比较n-1-i次, { if (a[j] < a[j+1]) { buf = a[j]; a[j] = a[j+1]; a[j+1] = buf; } } } for (i=0; i<n; ++i) { printf("%d\x20", a[i]); } printf("\n"); return 0; } 算法分析 冒泡排序一共要进行(n-1)次循环,每一次循环都要进行当前n-1次比较所以一共的比较次数是:(n-1) + (n-2) + (n-3) + … + 1 = n*(n-1)/2;所以冒泡排序的时间复杂度是 O(n^2)- 2024年09月19日
- 63 阅读
- 0 评论
- 68 点赞
-
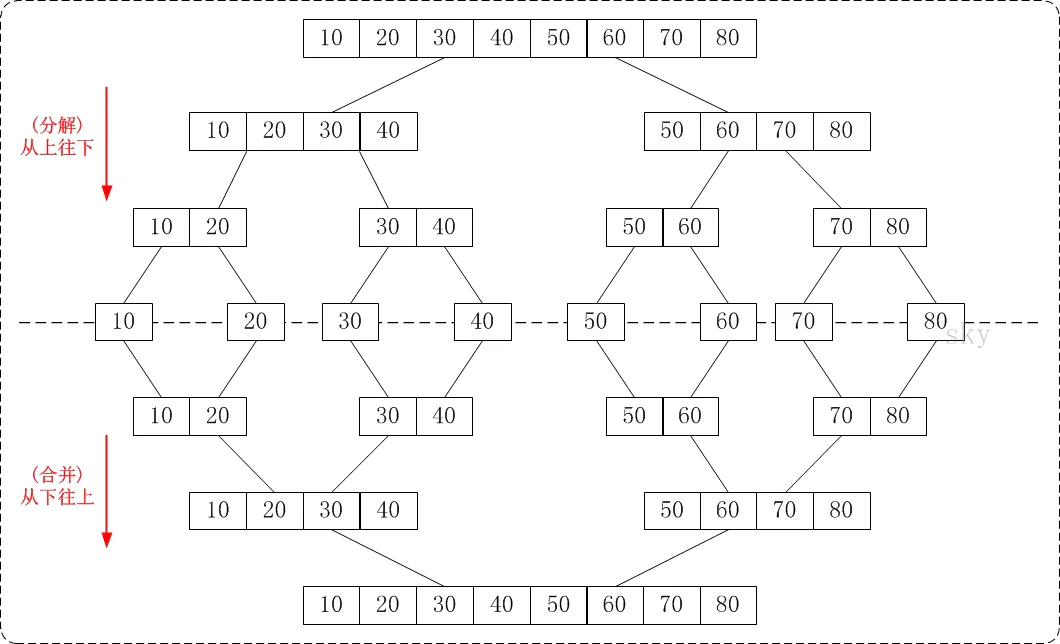
排序算法 - 3.归并排序(Merge Sort) 归并排序(Merge Sort) 归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。 public class Merge { public static void main(String[] args) throws Exception { Integer[] arr = {8, 4, 5, 7, 1, 3, 6, 2}; Merge.sort(arr); System.out.println(Arrays.toString(arr)); } private static Comparable[] assist;//归并所需要的辅助数组 /* 对数组a中的元素进行排序 */ public static void sort(Comparable[] a) { assist = new Comparable[a.length]; int lo = 0; int hi = a.length - 1; sort(a, lo, hi); } /* 对数组a中从lo到hi的元素进行排序 */ private static void sort(Comparable[] a, int lo, int hi) { if (hi <= lo) { return; } int mid = lo + (hi - lo) / 2; //对lo到mid之间的元素进行排序; sort(a, lo, mid); //对mid+1到hi之间的元素进行排序; sort(a, mid + 1, hi); //对lo到mid这组数据和mid到hi这组数据进行归并 merge(a, lo, mid, hi); } /* 对数组中,从lo到mid为一组,从mid+1到hi为一组,对这两组数据进行归并 */ private static void merge(Comparable[] a, int lo, int mid, int hi) { //lo到mid这组数据和mid+1到hi这组数据归并到辅助数组assist对应的索引处 int i = lo;//定义一个指针,指向assist数组中开始填充数据的索引 int p1 = lo;//定义一个指针,指向第一组数据的第一个元素 int p2 = mid + 1;//定义一个指针,指向第二组数据的第一个元素 //比较左边小组和右边小组中的元素大小,哪个小,就把哪个数据填充到assist数组中 while (p1 <= mid && p2 <= hi) { if (less(a[p1], a[p2])) { assist[i++] = a[p1++]; } else { assist[i++] = a[p2++]; } } //上面的循环结束后,如果退出循环的条件是p1<=mid,则证明左边小组中的数据已经归并完毕,如果退出循环的条件是p2<=hi,则证明右边小组的数据已经填充完毕; //所以需要把未填充完毕的数据继续填充到assist中,//下面两个循环,只会执行其中的一个 while (p1 <= mid) { assist[i++] = a[p1++]; } while (p2 <= hi) { assist[i++] = a[p2++]; } //到现在为止,assist数组中,从lo到hi的元素是有序的,再把数据拷贝到a数组中对应的索引处 for (int index = lo; index <= hi; index++) { a[index] = assist[index]; } } /* 比较v元素是否小于w元素 */ private static boolean less(Comparable v, Comparable w) { return v.compareTo(w) < 0; } /* 数组元素i和j交换位置 */ private static void exch(Comparable[] a, int i, int j) { Comparable t = a[i]; a[i] = a[j]; a[j] = t; } } 时间复杂度为O(nlogn); 归并排序的缺点: 需要申请额外的数组空间,导致空间复杂度提升,是典型的以空间换时间的操作。
- 2024年05月17日
- 34 阅读
- 0 评论
- 68 点赞
-
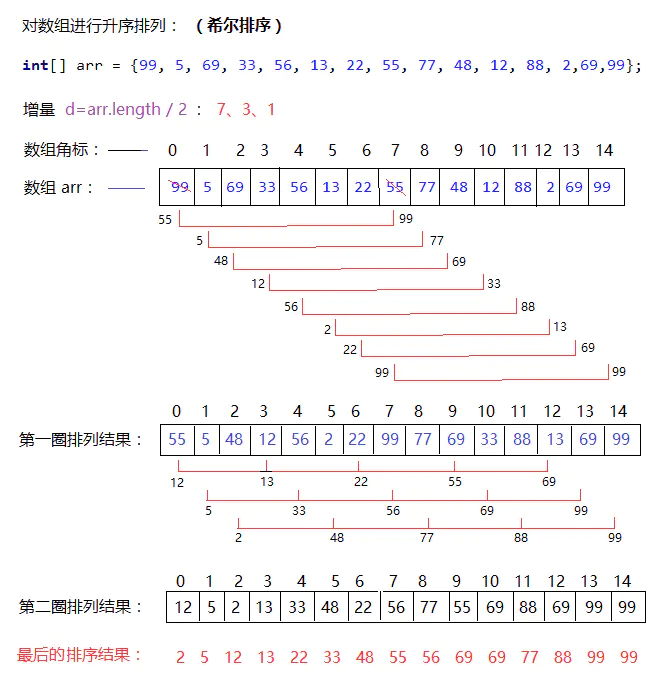
排序算法 - 2.希尔排序(Shell's Sort) 希尔排序(Shell's Sort)是插入排序的一种又称“缩小增量排序”(Diminishing Increment Sort),是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法。该方法因 D.L.Shell 于 1959 年提出而得名。 **希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至 1 时,整个文件恰被分成一组,算法便终止。** (注:为方便记忆算法,我习惯将其记作“三层for循环+if” ------ for(for(for(if)))) 2.步骤 希尔排序的基本步骤,在此我们选择增量gap=length/2,缩小增量继续以gap = gap/2的方式,这种增量选择我们可以用一个序列来表示,{n/2,(n/2)/2...1},称为增量序列。希尔排序的增量序列的选择与证明是个数学难题,我们选择的这个增量序列是比较常用的,也是希尔建议的增量,称为希尔增量,但其实这个增量序列不是最优的。此处我们做示例使用希尔增量。 public static void main(String[] args) { int[] arr = {99, 5, 69, 33, 56, 13, 22, 55, 77, 48, 12, 88, 2,69,99}; System.out.println("排序之前数组:"); printArray(arr); //希尔排序 insertionSort(arr); System.out.println("希尔排序后数组:"); System.out.println(Arrays.toString(arr)); } private static int[] insertionSort(int[] arr){ if(arr == null || arr.length <= 1){ return arr; } //希尔排序 升序 // arr.length==15 for (int d = arr.length / 2;d>0;d /= 2){ //d:增量 7 3 1 System.out.println("增量取值:" + d); for (int i = d; i < arr.length; i++){ //i:代表即将插入的元素角标,作为每一组比较数据的最后一个元素角标 //j:代表与i同一组的数组元素角标 for (int j = i-d; j>=0; j-=d){ //在此处-d 为了避免下面数组角标越界 // System.out.println("i:" + i + " j:" + j +" j+d="+(j+d)); if (arr[j] > arr[j + d]) {// j+d 代表即将插入的元素所在的角标 //符合条件,插入元素(交换位置) swap(arr,j,j+d); } } } /*测试:此段代码只为查看希尔排序的每次增量变化过程,正常写程序时不要添加星号注释的这部分代码*/ for (int m = 0; m < arr.length; m++) { System.out.print(arr[m] + " "); } System.out.println(""); /**/ } return arr; } /* 发现无论什么排序。都需要对满足条件的元素进行位置置换。 所以可以把这部分相同的代码提取出来,单独封装成一个函数。 */ public static void swap(int[] arr,int a,int b) { int temp = arr[a]; arr[a] = arr[b]; arr[b] = temp; } /* * 最近才知道打印数组不用自己写方法这么麻烦,java API中就有 Arrays.toString(arr); * 越简单的越容易忽略,这是最后一次自己写这个方法,以后就用自带的方法 */ public static void printArray(int[] arr) { System.out.print("["); for(int x=0; x<arr.length; x++) { if(x!=arr.length-1){ System.out.print(arr[x]+", "); }else{ System.out.println(arr[x]+"]"); } } } 希尔排序的执行时间依赖于增量序列。 希尔排序耗时的操作有:比较 + 后移赋值。 时间复杂度情况如下:(n指待排序序列长度) 1) 最好情况:序列是正序排列,在这种情况下,需要进行的比较操作需(n-1)次。后移赋值操作为0次。即O(n) 2) 最坏情况:O(nlog2n)。 3) 渐进时间复杂度(平均时间复杂度):O(nlog2n)
- 2023年06月28日
- 85 阅读
- 0 评论
- 35 点赞
-
-
排序算法 - 6.选择排序 选择排序的原理: 选择排序在开始的时候,先扫描整个列表,以找到列表中的最小元素,然后将这个元素与第一个元素进行交换。这样最小元素就放到它的最终位置上。然后,从第二个元素开始扫描,找到n-1个元素中的最小元素,然后再与第二个元素进行交换。以此类推,直到第n-1个元素(如果前n-1个元素都已在最终位置,则最后一个元素也将在最终位置上)。 选择排序的基本思想是: 每一趟在n − i + 1 ( i = 1 , 2 , . . . , n − 1 ) 个元素中选择最小的元素,并将其作为有序序列中第 i 个元素。 public static void selectionSort(int[] array) { int len = array.length; int minIndex; //最后一个元素最后已经是排完的状态了,无需再排 for (int i = 0; i < len - 1; i++) { //默认认为当前序列的第一个元素是当前序列中的最小/大元素 minIndex = i; //找到更小的元素 for (int j = i + 1; j < len; j++) { if (array[j] < array[minIndex]) { minIndex = j; } } //交换最小/大元素和第一个元素的位置 if (minIndex != i) { int temp = array[minIndex]; array[minIndex] = array[i]; array[i] = temp; } } } 算法分析 表现最稳定的排序算法之一,因为无论什么数据进去都是O(n2)的时间复杂度,所以用到它的时候,数据规模越小越好。唯一的好处可能就是不占用额外的内存空间了吧。理论上讲,选择排序可能也是平时排序一般人想到的最多的排序方法了吧。
- 2022年07月16日
- 57 阅读
- 0 评论
- 87 点赞